
linux kernel
kernel pwn学习(二)
内核堆管理机制(参考:Kernel 2 - 内核堆基础与 SLUB 分配器 (nebuu.la))
Buddy System
伙伴系统(Buddy System):区级别的内存管理系统,以 页 为粒度进行内存分配,并管理所有物理内存。在内存的分配与释放方面,Buddy System 按照空闲页面的连续大小进行分阶管理,表现为zone结构体中的 free_area:
其中每块内存大小为 2^order * page_size
Slab allocator
SLAB分配器用于管理从 Buddy System 申请到的内存,分割成多个小的 object 返回给上层调用者。
slab 结构体
- 复用
page结构体 - 作为单份
Object池 - 其中关键成员包括:
slab_cache:kmem_cache类型,指向对应的内存池slab_list:多个相同用途的slab组成的双向链表freelist:指向空闲对象的单向链表,以NULL结尾
kmem_cache 结构体
- 所有
kmem_cache构成双向链表,且有一个全局数组kmalloc_caches存放通用kmem_cache,大小为2的幂次方,在分配时,其会选择一个大于其大小的2的幂次方的值。(此外,为了减少内存碎片,还有一些特殊大小的slub,例如96字节和192字节。) - 其中关键成员包括:
cpu_slab:struct kmem_cache_cpu __percpu *类型,指向当前CPU独占的内存池(同一个CPU访问自己的内存池不用上锁,优先从中分配、释放,效率高,通过gs寄存器作为percpu基址进行寻址,做题时先绑定CPU)node:struct kmem_cache_node *[]类型,存放多个不同node的后备内存池
/* 84 */ struct kmem_cache {
/* 85 */ struct kmem_cache_cpu __percpu *cpu_slab;
/* 86 */ /* Used for retrieving partial slabs, etc. */
/* 87 */ slab_flags_t flags;
/* 88 */ unsigned long min_partial;
/* 89 */ unsigned int size; /* The size of an object including metadata */
/* 90 */ unsigned int object_size;/* The size of an object without metadata */
/* 91 */ struct reciprocal_value reciprocal_size;
/* 92 */ unsigned int offset; /* Free pointer offset */
/* 93 */ #ifdef CONFIG_SLUB_CPU_PARTIAL
/* 94 */ /* Number of per cpu partial objects to keep around */
/* 95 */ unsigned int cpu_partial;
/* 96 */ #endif
------
/* 136 */ };
 *
*
kmem_cache_cpu 结构体
- 对于一个
kmem_cache,每个CPU都有与其对应且独立的kmem_cache_cpu - 其中关键成员包括:
freelist:指向下一个可用对象(object)的指针,其freelist与slab中的freelist不同(仅当slab对象被挂在partial链表中时,其freelist才有可能被用到;分配和释放优先考虑kmem_cache_cpu中的freelist)slab:指向当前用以进行内存分配的slabpartial:需要开启编译选项CONFIG_SLUB_CPU_PARTIAL=y,percpu的partial slab链表,链表上为仍有一定空闲对象的slab
// >>> include/linux/slub_def.h:43
/* 43 */ struct kmem_cache_cpu {
/* 44 */ void **freelist; /* Pointer to next available object */
/* 45 */ unsigned long tid; /* Globally unique transaction id */
/* 46 */ struct page *page; /* The slab from which we are allocating */
/* 47 */ #ifdef CONFIG_SLUB_CPU_PARTIAL
/* 48 */ struct page *partial; /* Partially allocated frozen slabs */
/* 49 */ #endif
-------
/* 53 */ };
kmem_cache_node 结构体
- 每个节点(即三级结构
节点 -> 区 -> 页中的节点)对应的后备内存池,当 percpu 的独占内存池耗尽后便会从对应 node 的后备内存池尝试分配 - 不同于
kmem_cache_cpu只有一个slab,kmem_cache_node会维护多个slab,对kmem_cache_cpu的slab进行分配和回收 - 其中关键成员包括:
partial:同上,包含partial slabfull:不常用,连接没有空闲对象的slab
分配过程
slub allocator从kmem_cache_cpu上取object,若kmem_cache_cpu上存在,则直接返回;- 若不存在,该
slub会被加入到kmem_cache_node中的full链表,并从partial链表中取一个slub挂载到kmem_cache_cpu上,然后重复第一步的操作 - 若
kmem_cache_cpu的partial链表也空了,那么会向buddy system请求分配新的内存页,划分为多个object,并给到kmem_cache_cpu,取出object并返回
释放过程
关键于被释放的 object所属的slub位于哪里。
若其 slub现在位于 kmem_cache_cpu,则直接头插法插入当前 kmem_cache_cpu的 freelist链表。
若其 slub属于 kmem_cache_node的 partial链表上的 slub,则同样通过头插法插入对应的 slub中的 freelist。
若其 slub属于 kmem_cache_node的 full链表上的 slub,则会使其成为对应 slub的 freelist的头结点,并将该 slub从 full链表迁移到 partial
常用结构体、函数及利用方法
tty 设备结构体
tty 设备在 /dev 下的一个伪终端设备 ptmx 。
tty_struct(kmalloc-1k | GFP_KERNEL_ACCOUNT)
定义:
定义于 include/linux/tty.h 中,当我们打开 /dev/ptmx 时(init文件需要挂载 pts)会在内核中分配一个 tty_struct 结构体,起始位置有魔数为 0x5401
struct tty_struct {
int magic;
struct kref kref;
struct device *dev; /* class device or NULL (e.g. ptys, serdev) */
struct tty_driver *driver;
const struct tty_operations *ops;
int index;
/* Protects ldisc changes: Lock tty not pty */
struct ld_semaphore ldisc_sem;
struct tty_ldisc *ldisc;
struct mutex atomic_write_lock;
struct mutex legacy_mutex;
struct mutex throttle_mutex;
struct rw_semaphore termios_rwsem;
struct mutex winsize_mutex;
/* Termios values are protected by the termios rwsem */
struct ktermios termios, termios_locked;
char name[64];
unsigned long flags;
int count;
struct winsize winsize; /* winsize_mutex */
struct {
spinlock_t lock;
bool stopped;
bool tco_stopped;
unsigned long unused[0];
} __aligned(sizeof(unsigned long)) flow;
struct {
spinlock_t lock;
struct pid *pgrp;
struct pid *session;
unsigned char pktstatus;
bool packet;
unsigned long unused[0];
} __aligned(sizeof(unsigned long)) ctrl;
int hw_stopped;
unsigned int receive_room; /* Bytes free for queue */
int flow_change;
struct tty_struct *link;
struct fasync_struct *fasync;
wait_queue_head_t write_wait;
wait_queue_head_t read_wait;
struct work_struct hangup_work;
void *disc_data;
void *driver_data;
spinlock_t files_lock; /* protects tty_files list */
struct list_head tty_files;
#define N_TTY_BUF_SIZE 4096
int closing;
unsigned char *write_buf;
int write_cnt;
/* If the tty has a pending do_SAK, queue it here - akpm */
struct work_struct SAK_work;
struct tty_port *port;
} __randomize_layout;
/* Each of a tty's open files has private_data pointing to tty_file_private */
struct tty_file_private {
struct tty_struct *tty;
struct file *file;
struct list_head list;
};
/* tty magic number */
#define TTY_MAGIC 0x5401
泄露内核基地址(.text段)
tty_operations会被初始化为全局变量 ptm_unix98_ops或者 pyt_unix98_ops ,开启了 kaslr 的内核在内存中的偏移依然以内存页为粒度,故我们可以通过比对 tty_operations 地址的低三16进制位来判断是 ptm_unix98_ops 还是 pty_unix98_ops
cat /proc/kallsyms | grep 'ptm_unix98_ops'
泄露内核堆地址(内核线性映射区)
tty_struct中的 dev与 driver是通过 kmalloc分配的,可以通过这两个成员泄露内核地址。
劫持内核执行流
对这个 tty设备(例如 /dev/ptmx)进行相应操作(如 write、ioctl)时便会执行我们在 tty_operations中布置好的恶意函数指针,从而劫持内核执行流。参数可控, rdi即为 tty_struct的地址。
struct tty_operations {
struct tty_struct * (*lookup)(struct tty_driver *driver,struct file *filp, int idx);
int (*install)(struct tty_driver *driver, struct tty_struct *tty);
void (*remove)(struct tty_driver *driver, struct tty_struct *tty);
int (*open)(struct tty_struct * tty, struct file * filp);
void (*close)(struct tty_struct * tty, struct file * filp);
void (*shutdown)(struct tty_struct *tty);
void (*cleanup)(struct tty_struct *tty);
int (*write)(struct tty_struct * tty,const unsigned char *buf, int count);
int (*put_char)(struct tty_struct *tty, unsigned char ch);
void (*flush_chars)(struct tty_struct *tty);
unsigned int (*write_room)(struct tty_struct *tty);
unsigned int (*chars_in_buffer)(struct tty_struct *tty);
int (*ioctl)(struct tty_struct *tty,unsigned int cmd, unsigned long arg);
long (*compat_ioctl)(struct tty_struct *tty,unsigned int cmd, unsigned long arg);
void (*set_termios)(struct tty_struct *tty, struct ktermios * old);
void (*throttle)(struct tty_struct * tty);
void (*unthrottle)(struct tty_struct * tty);
void (*stop)(struct tty_struct *tty);
void (*start)(struct tty_struct *tty);
void (*hangup)(struct tty_struct *tty);
int (*break_ctl)(struct tty_struct *tty, int state);
void (*flush_buffer)(struct tty_struct *tty);
void (*set_ldisc)(struct tty_struct *tty);
void (*wait_until_sent)(struct tty_struct *tty, int timeout);
void (*send_xchar)(struct tty_struct *tty, char ch);
int (*tiocmget)(struct tty_struct *tty);
int (*tiocmset)(struct tty_struct *tty,
unsigned int set, unsigned int clear);
int (*resize)(struct tty_struct *tty, struct winsize *ws);
int (*get_icount)(struct tty_struct *tty,
struct serial_icounter_struct *icount);
int (*get_serial)(struct tty_struct *tty, struct serial_struct *p);
int (*set_serial)(struct tty_struct *tty, struct serial_struct *p);
void (*show_fdinfo)(struct tty_struct *tty, struct seq_file *m);
#ifdef CONFIG_CONSOLE_POLL
int (*poll_init)(struct tty_driver *driver, int line, char *options);
int (*poll_get_char)(struct tty_driver *driver, int line);
void (*poll_put_char)(struct tty_driver *driver, int line, char ch);
#endif
int (*proc_show)(struct seq_file *, void *);
} __randomize_layout;
work_for_cpu_fn函数
定义:
struct work_for_cpu {
struct work_struct work;
long (*fn)(void *);
void *arg;
long ret;
};
static void work_for_cpu_fn(struct work_struct *work)
{
struct work_for_cpu *wfc = container_of(work, struct work_for_cpu, work);
wfc->ret = wfc->fn(wfc->arg);
}
/*相当于执行
static void work_for_cpu_fn(size_t * args)
{
args[6] = ((size_t (*) (size_t)) (args[4](args[5]));
}
*/
利用:
可以将 tty_struct劫持为如下形式:(劫持函数表 tty_operations中的 ioctl 为work_for_cpu_fn)
tty_struct[4] = (size_t)commit_creds;
tty_struct[5] = (size_t)init_cred;
ioctl(tty_fd, 233, 233);
/*相当于执行
((void*)tty_struct[4])(tty_struct[5]);
commit_creds(&init_cred);
*/
tty_file_private (kmalloc-32 | GFP_KERNEL)
定义:
struct tty_file_private {
struct tty_struct *tty;
struct file *file;
struct list_head list;
};
打开 /dev/ptmx 时会分配 tty_file_private 并且该结构体的 tty 指针会指向 tty_struct 。(UAF用于泄露地址)
相应的,当关闭打开的 /dev/ptmx 时会释放相应结构。
seq_file 相关
seq_operation(kmalloc-32 | GFP_KERNEL_ACCOUNT)
定义:
- 为了简化操作,在内核
seq_file系列接口中为file结构体提供了private data成员seq_file结构体(无法打开来申请内存空间)。 -
通过
open("/proc/self/stat", O_RDONLY)来打开,从而申请seq_operation这个结构体。-
stat_open() <--- stat_proc_ops.proc_open single_open_size() single_open() //可以分配seq_operations 结构体
-
- 该结构体定义于
/include/linux/seq_file.h当中。
struct seq_file {
char *buf;
size_t size;
size_t from;
size_t count;
size_t pad_until;
loff_t index;
loff_t read_pos;
struct mutex lock;
const struct seq_operations *op;
int poll_event;
const struct file *file;
void *private;
};
struct seq_operations {
void * (*start) (struct seq_file *m, loff_t *pos);
void (*stop) (struct seq_file *m, void *v);
void * (*next) (struct seq_file *m, void *v, loff_t *pos);
int (*show) (struct seq_file *m, void *v);
};
泄露内核基地址(.text 段)
start即为函数 single_start函数
cat /proc/kallsyms | grep 'single_start'
劫持内核执行流
当 read 一个 stat 文件时,内核会调用其 proc_ops 的 proc_read_iter 指针,其默认值为 seq_read_iter() 函数
只需要控制 seq_operations->start 后再用 read读取对应 stat 文件便能控制内核执行流(但是参数不可控,可以配合 pt_reg结构体使用)。
调试时可在 seq_read_iter函数处下断点。
可以选择覆盖 start函数指针为一个 add_rsp_xxx_ret类似的 gadget,将栈抬到 pt_reg结构体处,从而执行ROP。
ldt_struct结构体
ldt_struct: kmalloc-16(slub)/kmalloc-32(slab)
在内核中与 LDT 相关联的结构体为 ldt_struct
struct ldt_struct {
struct desc_struct * entries; /* 0 0x8 */
unsigned int nr_entries; /* 0x8 0x4 */
int slot; /* 0xc 0x4 */
/* size: 16, cachelines: 1, members: 3 */
/* last cacheline: 16 bytes */
};
modify_ldt 系统调用可以用来操纵对应进程的 ldt_struct
SYSCALL_DEFINE3(modify_ldt, int , func , void __user * , ptr ,
unsigned long , bytecount)
{
int ret = -ENOSYS;
switch (func) {
case 0:
ret = read_ldt(ptr, bytecount);
break;
case 1:
ret = write_ldt(ptr, bytecount, 1);
break;
case 2:
ret = read_default_ldt(ptr, bytecount);
break;
case 0x11:
ret = write_ldt(ptr, bytecount, 0);
break;
}
/*
* The SYSCALL_DEFINE() macros give us an 'unsigned long'
* return type, but tht ABI for sys_modify_ldt() expects
* 'int'. This cast gives us an int-sized value in %rax
* for the return code. The 'unsigned' is necessary so
* the compiler does not try to sign-extend the negative
* return codes into the high half of the register when
* taking the value from int->long.
*/
return (unsigned int)ret;
}
泄露地址:modify_ldt 系统调用 - read_ldt()
static int read_ldt(void __user *ptr, unsigned long bytecount)
{
//...
if (copy_to_user(ptr, mm->context.ldt->entries, entries_size)) {
retval = -EFAULT;
goto out_unlock;
}
//...
out_unlock:
up_read(&mm->context.ldt_usr_sem);
return retval;
}
read_ldt() 直接调用 copy_to_user 向用户地址空间拷贝数据 ,若是能够控制 ldt->entries 便能够完成内核的任意地址读,由此泄露出内核数据。
copy_to_user() 的一个特性:对于非法地址,其并不会造成 kernel panic,只会返回一个非零的错误码。我们可以多次修改 ldt->entries 并多次调用 modify_ldt() 以 爆破内核 .text 段地址与 page_offset_base ,若是成功命中,则 modify_ldt 会返回给我们一个非负值。
但是由于 Hardened usercopy 的存在,对于直接拷贝代码段上数据的行为会导致 kernel panic,但是在page_offset_base + 0x9d000 的地方(非代码段)存储着 secondary_startup_64 函数的地址,于是思路就是爆破page_offset_base的地址
绕过hardened usercopy
通过 fork创建子进程,然后使用子进程来 read_ldt ,在 fork时,会将父进程的 ldt拷贝给子进程
setxattr系统调用 GFP_KERNEL
setxattr
可以通过以下方式使用:
#include <sys/xattr.h>
setxattr("/exploit", "username", value, size, 0); //第一个参数指定一个存在的文件,第二个参数随便
该系统调用会走到下面这个函数:可以看到能够进行任意大小的 object 分配,size可控且内容可控,但是之后会被释放掉
static long
setxattr(struct dentry *d, const char __user *name, const void __user *value,
size_t size, int flags)
{
//...
kvalue = kvmalloc(size, GFP_KERNEL);
if (!kvalue)
return -ENOMEM;
if (copy_from_user(kvalue, value, size)) {
//,..
kvfree(kvalue);
return error;
}
利用- 结合userfaultfd来堆占位
我们申请一块连续的两页内存:
| memory1: size=pagesize | memory2: size=pagesize |
随后,我们为第二部分的内存,注册 userfaultfd , 使得访问到这里时直接卡住.
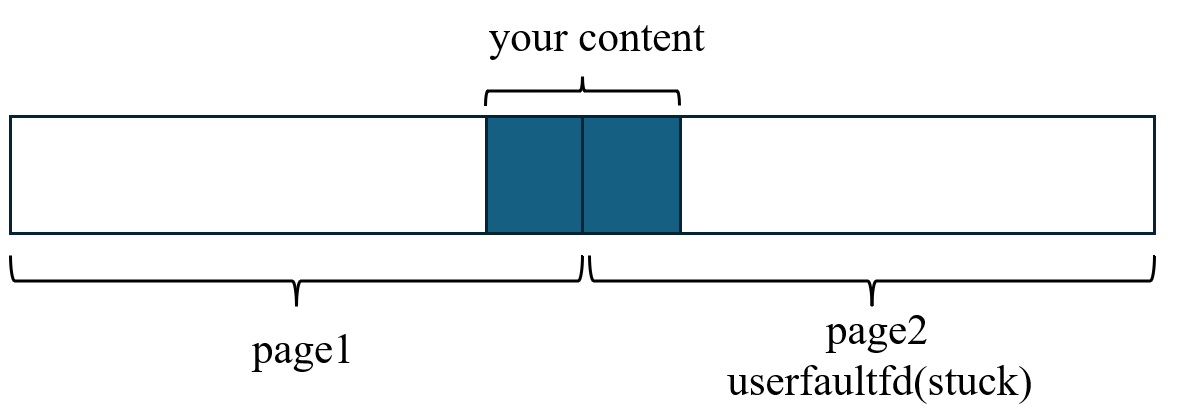
代码如下:
pwn_addr = mmap(NULL, 0x2000, PROT_READ | PROT_WRITE, MAP_ANONYMOUS | MAP_PRIVATE, -1, 0);
register_userfaultfd_for_thread_stucking(&monitor_setx, (void*)((size_t)pwn_addr + 0x1000), 0x1000);
*(size_t*)((size_t)pwn_addr + 0x1000 - 8) = add_rsp_0x1f8 + kernel_offset;
setxattr("/init", "ltfall", (char*)((size_t)pwn_addr + 0x1000 - 8), 0x20, 0);
可以看到,我们上面便申请了一个 kmalloc-32的 obj,并写入了 add_rsp_0x1f8的 gadget
user_key_payload (kmalloc-any, GFP_KERNEL)
定义:
struct user_key_payload {
struct rcu_head rcu; /* RCU destructor */
unsigned short datalen; /* length of this data */
//以上总共0x18字节
char data[] __aligned(__alignof__(u64)); /* actual data */
};
rcu_head结构体:
struct callback_head {
struct callback_head *next;
void (*func)(struct callback_head *head);
} __attribute__((aligned(sizeof(void *))));
#define rcu_head callback_head
在内核当中存在一个用于密钥管理的子系统,内核提供了 add_key() 系统调用进行密钥的创建,并提供了 keyctl() 系统调用进行密钥的读取、更新、销毁等功能。
#include <sys/types.h>
#include <keyutils.h>
key_serial_t add_key(const char *type, const char *description,
const void *payload, size_t plen,key_serial_t keyring);
//...
#include <asm/unistd.h>
#include <linux/keyctl.h>
#include <unistd.h>
long syscall(__NR_keyctl, int operation, __kernel_ulong_t arg2,
__kernel_ulong_t arg3, __kernel_ulong_t arg4,
__kernel_ulong_t arg5);
当我们调用 add_key() 分配一个带有 description 字符串的、类型为 "user" 的、长度为 plen 的内容为 payload 的密钥时,内核会经历如下过程:
- 首先会在内核空间中分配
obj1与obj2,分配flag为GFP_KERNEL,用以保存description(字符串,最大大小为4096)、payload(普通数据,大小无限制) - 分配
obj3保存description,分配obj4保存payload,分配flag皆为GFP_KERNEL - 释放
obj1与obj2,返回密钥id
总而言之在保存 description和 payload时都会分别利用中间体 obj
调用 keyctl_read系统调用越界读
控制 user_key_payload 结构体中的 datalen为一个大于其 payload长度的数字,读到其他被释放的 user_key_payload ,即可读到 rcu->func 和 rcu->func 。
泄露内核基地址
利用 key_revoke来销毁密钥时,rcu->func将会被赋值为 user_free_payload_rcu函数的地址。
int key_revoke(int keyid)
{
return syscall(__NR_keyctl, KEYCTL_REVOKE, keyid, 0, 0, 0);
}
cat /proc/kallsyms | grep 'user_free_payload_rcu'
泄露内核堆地址
读取 rcu->func泄露堆地址
pipe 管道相关
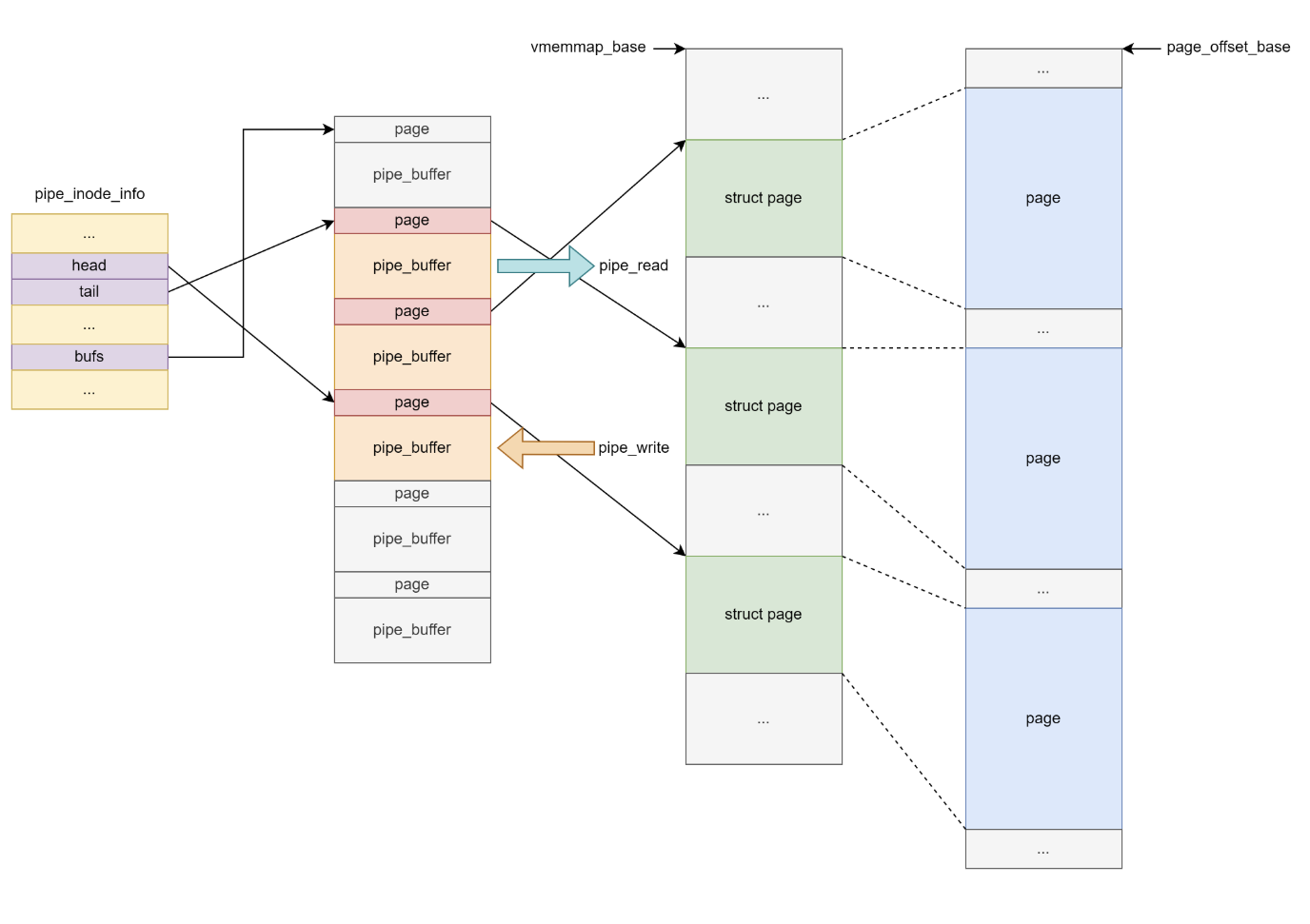
pipe_inode_info
定义:
当我们 void pipe(int fd[])打开管道时,会创建两个结构体,分别为 pipe_inode_info (kmalloc-192 | GFP_KERNEL_ACCOUNT)
struct pipe_inode_info {
struct mutex mutex;
wait_queue_head_t rd_wait, wr_wait;
unsigned int head;
unsigned int tail;
unsigned int max_usage;
unsigned int ring_size;
#ifdef CONFIG_WATCH_QUEUE
bool note_loss;
#endif
unsigned int nr_accounted;
unsigned int readers;
unsigned int writers;
unsigned int files;
unsigned int r_counter;
unsigned int w_counter;
struct page *tmp_page;
struct fasync_struct *fasync_readers;
struct fasync_struct *fasync_writers;
struct pipe_buffer *bufs; //***
struct user_struct *user;
#ifdef CONFIG_WATCH_QUEUE
struct watch_queue *watch_queue;
#endif
};
pipe_inode_info->bufs 为一个动态分配的结构体数组,因此我们可以利用他来泄露出内核的“堆”上地址
和 pipe_buffer (kmalloc-1k | GFP_KERNEL_ACCOUNT),往 pipe_fd[1]中写入数据成功后才会初始化 pipe_buffer
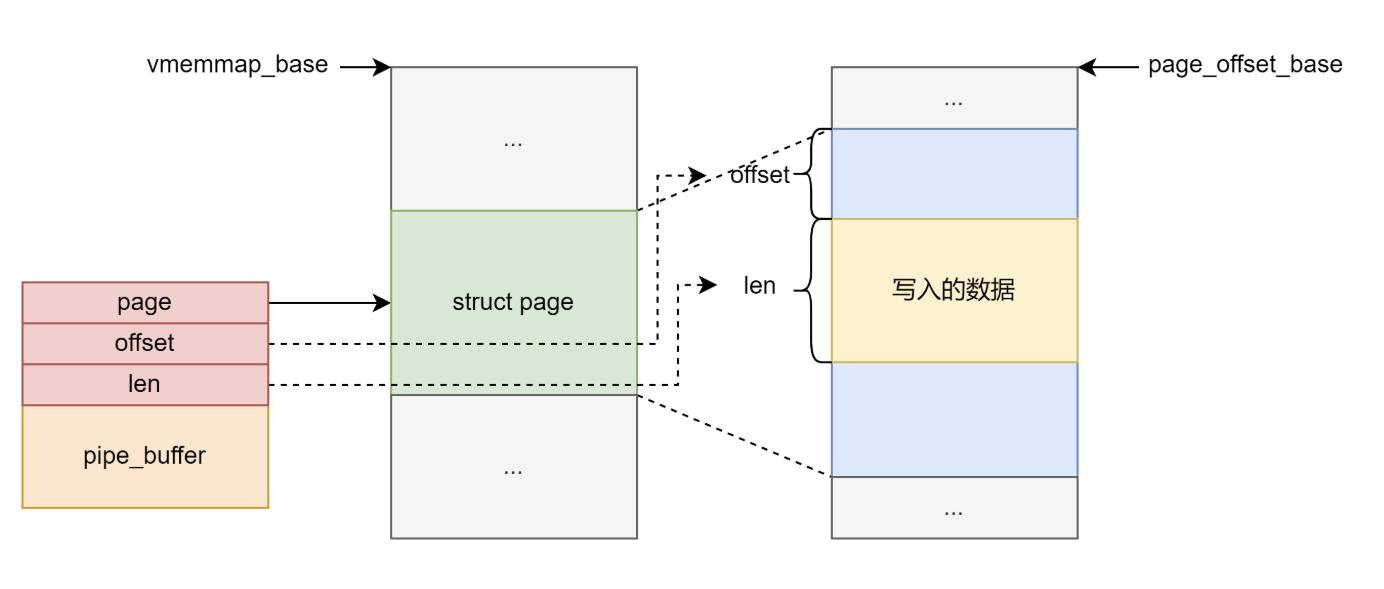
struct pipe_buffer {
struct page *page;
unsigned int offset, len;
const struct pipe_buf_operations *ops;
unsigned int flags;
unsigned long private;
};
void pipe_buffer_init(){
puts("[*] pipe buffer init");
for (int i = 0; i < MAX_PIPE_COUNT; ++i) {
uint32_t k = i;
write(pipe_fd[i][1], "QQEEDD", 8);
write(pipe_fd[i][1], &k, sizeof(uint32_t));
}
}
/*
pipe_fd[i][0]:这是管道的 读取端 (Read End)。通过这个文件描述符从管道缓冲区中读取数据。
pipe_fd[i][1]:这是管道的 写入端 (Write End)。通过这个文件描述符向管道缓冲区中写入数据。
*/
具体到每个 pipe_buffer 其中的 offset 和 len 标记了 pipe_buffer 对应内存页中的数据。
可以通过系统调用更改pipe_buffer的大小
当选项为 F_SETPIPE_SZ 其会修改当前pipe的bufs数组大小为第三个参数 (arg>>12)*sizeof(*bufs) 注意arg»12(2^12=0x1000)必须是2的幂次方 sizeof(*bufs)=64
void pipe_buffer_resize(){
puts("[*] pipe buffer resize");
for(int i = 0; i < MAX_PIPE_COUNT; i++){
if (fcntl(pipe_fd[i][1], F_SETPIPE_SZ, 0x1000 * 4) < 0) {
perror("resize pipe");
exit(0);
}
}
}
其中 pipe_buf_operations结构体:
struct pipe_buf_operations {
/*
* ->confirm() verifies that the data in the pipe buffer is there
* and that the contents are good. If the pages in the pipe belong
* to a file system, we may need to wait for IO completion in this
* hook. Returns 0 for good, or a negative error value in case of
* error. If not present all pages are considered good.
*/
int (*confirm)(struct pipe_inode_info *, struct pipe_buffer *);
/*
* When the contents of this pipe buffer has been completely
* consumed by a reader, ->release() is called.
*/
void (*release)(struct pipe_inode_info *, struct pipe_buffer *);
/*
* Attempt to take ownership of the pipe buffer and its contents.
* ->try_steal() returns %true for success, in which case the contents
* of the pipe (the buf->page) is locked and now completely owned by the
* caller. The page may then be transferred to a different mapping, the
* most often used case is insertion into different file address space
* cache.
*/
bool (*try_steal)(struct pipe_inode_info *, struct pipe_buffer *);
/*
* Get a reference to the pipe buffer.
*/
bool (*get)(struct pipe_inode_info *, struct pipe_buffer *);
}
泄露内核基地址
pipe_buffer->pipe_buf_operations指向全局函数表
劫持程序执行流
当我们利用 close(pipe_fd[1]);close(pipe_fd[0]);关闭管道两端时,会触发 pipe_buffer->pipe_bufer_operations->release 指针,因此可以覆写pipe_buf_operations函数表中的release指针或劫持函数表到可控区域,便可劫持程序执行流。其 rdi和 rsi均可控,rdi为 struct pipe_inode_info,rsi为 struct pipe_buffer。
调试时在 pipe_buf_release处下断点。
一个栈迁移的JOP gadget(不知道怎么搜这种类型的gadget),实现效果是
RDX!=RCX时PUSH_RSI_POP_RSP_POP_RBX_POP_RBP_POP_R12_RET可以用于此处栈迁移
# exploooosion @ Exploooosion in ~/mypwn/linux_kernel/Digging-into-Kernel-3/core workenv [15:24:16]
$ objdump -D --start-address=0xffffffff81250c9d --stop-address=0xffffffff81250cbf ../vmlinux
../vmlinux: 文件格式 elf64-x86-64
Disassembly of section .text:
ffffffff81250c9d <simple_write_begin+0x12d>:
ffffffff81250c9d: 56 push %rsi
ffffffff81250c9e: 5c pop %rsp
ffffffff81250c9f: 48 39 d1 cmp %rdx,%rcx
ffffffff81250ca2: 72 e1 jb ffffffff81250c85 <simple_write_begin+0x115>
ffffffff81250ca4: 5b pop %rbx
ffffffff81250ca5: 31 c0 xor %eax,%eax
ffffffff81250ca7: 5d pop %rbp
ffffffff81250ca8: 41 5c pop %r12
ffffffff81250caa: e9 91 25 db 00 jmp ffffffff82003240 <__x86_return_thunk>
ffffffff81250caf: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
ffffffff81250cb4: 0f b6 4e 51 movzbl 0x51(%rsi),%ecx
ffffffff81250cb8: b8 00 10 00 00 mov $0x1000,%eax
ffffffff81250cbd: 48 d3 shl %cl,%rax
(workenv)
# exploooosion @ Exploooosion in ~/mypwn/linux_kernel/Digging-into-Kernel-3/core workenv [15:27:03]
$ objdump -D --start-address=0xffffffff82003240 --stop-address=0xffffffff82003250 ../vmlinux
../vmlinux: 文件格式 elf64-x86-64
Disassembly of section .text:
ffffffff82003240 <__x86_return_thunk>:
ffffffff82003240: c3 ret
ffffffff82003241: cc int3
ffffffff82003242: 0f ae e8 lfence
ffffffff82003245: eb f9 jmp ffffffff82003240 <__x86_return_thunk>
ffffffff82003247: cc int3
(workenv)
ps:可以通过pwntools寻找
from pwn import *
context(arch = 'amd64', os = 'linux')
elf = ELF('vmlinux')
for x in elf.search(asm('push rsi; pop rsp;'), executable = True):
print elf.disasm(address = x, n_bytes = 0x40)
print
System V 消息队列
在 Linux kernel 中有着一组 system V 消息队列相关的系统调用:
- msgget:创建一个消息队列
- msgsnd:向指定消息队列发送消息
- msgrcv:从指定消息队列接接收消息
当我们创建一个消息队列时,在内核空间中会创建一个 msg_queue 结构体,其表示一个消息队列:
/* one msq_queue structure for each present queue on the system */
struct msg_queue {
struct kern_ipc_perm q_perm;
time64_t q_stime; /* last msgsnd time */
time64_t q_rtime; /* last msgrcv time */
time64_t q_ctime; /* last change time */
unsigned long q_cbytes; /* current number of bytes on queue */
unsigned long q_qnum; /* number of messages in queue */
unsigned long q_qbytes; /* max number of bytes on queue */
struct pid *q_lspid; /* pid of last msgsnd */
struct pid *q_lrpid; /* last receive pid */
struct list_head q_messages;
struct list_head q_receivers;
struct list_head q_senders;
} __randomize_layout;
msg_msg (kmalloc-any | GFP_KERNEL_ACCOUNT)
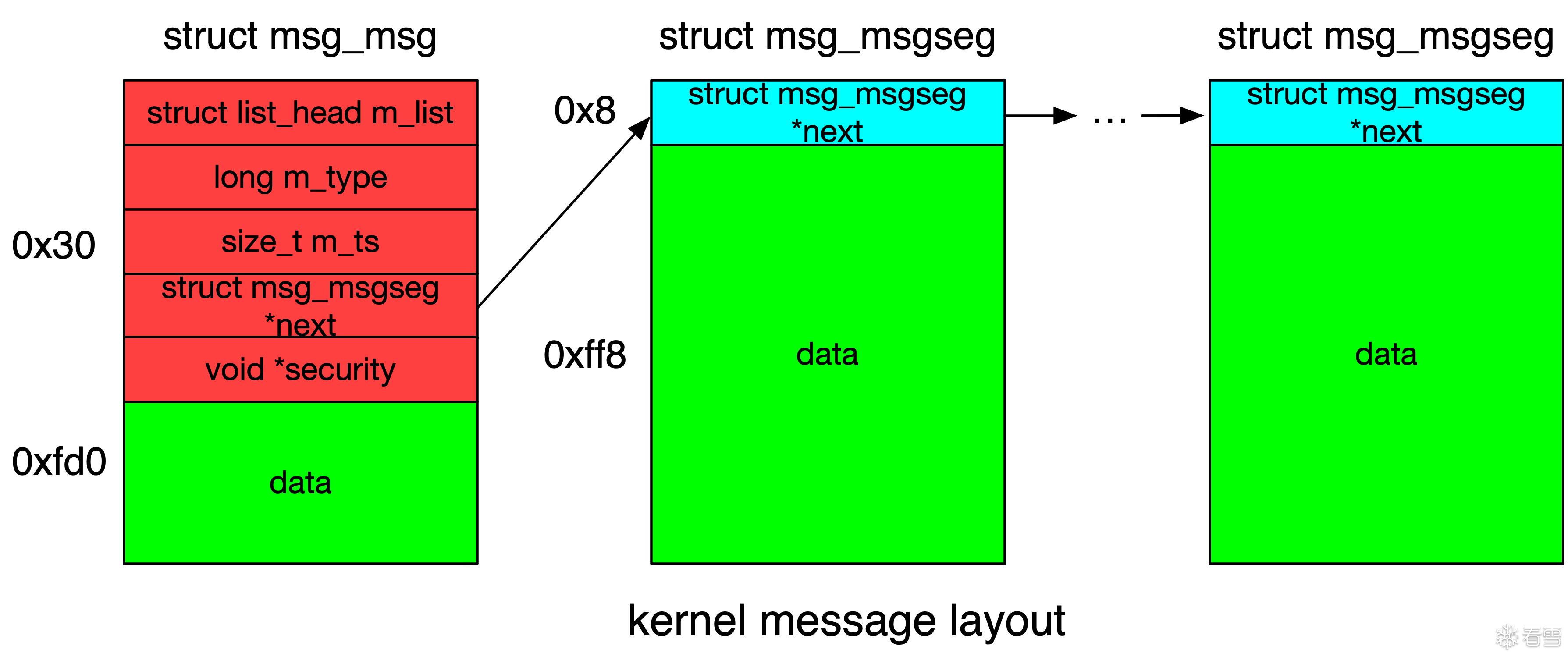
struct msg_msg {
struct list_head m_list; // 只有一条消息时,指向msg_queue的q_messages /* 0 0x10 */
long int m_type; /* message text size */ /* 0x10 0x8 */
size_t m_ts; /* 0x18 0x8 */
struct msg_msgseg * next; /* 0x20 0x8 */
void * security; /* 0x28 0x8 */
/* size: 48, cachelines: 1, members: 5 */
/* last cacheline: 48 bytes */
};
struct list_head{
struct msg_msg* next;
struct msg_msg* prev;
}
msg_queue 和 msg_msg 构成双向链表
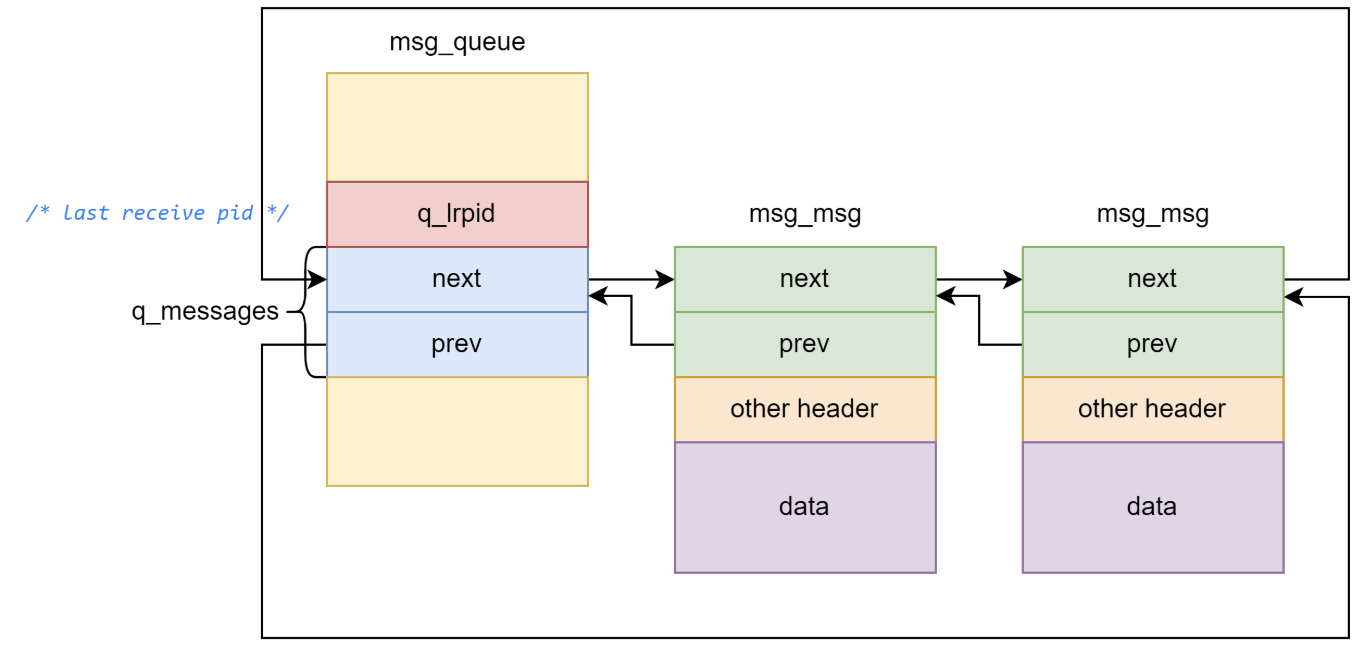
msg_queue 的大小基本上是固定的,但是 msg_msg 作为承载消息的本体其大小是可以随着消息大小的改变而进行变动的
当我们单次发送 大于【一个页面大小 - header size】 大小的消息时,内核会额外补充添加 msg_msgseg 结构体,其与 msg_msg 之间形成如下单向链表结构:单个 msg_msgseg 的大小最大为一个页面大小
利用
越界数据读取
在拷贝数据时对长度的判断主要依靠的是 msg_msg->m_ts,我们不难想到的是:若是我们能够控制一个 msg_msg 的 header,将其 m_ts 成员改为一个较大的数,我们就能够越界读取出最多将近一张内存页大小的数据
条件竞争(Race condition)
double fetch
满足以下可能情况:
- 不直接将用户空间的数据传入内核空间,只传入指针
- 后续操作会不止一次使用到该指针
比如第一次使用指针校验用户空间的数据信息。先开辟一个线程不断地改写指针指向的数据信息,当前线程不断将数据信息合法化,形成竞争,总会存在经校验后的信息在使用时总会不合法的情况。
userfaultfd系统调用(linux-5.11及以后不能使用)
大致功能:
- 利用
mmap函数分配一块匿名内存(没有实际物理内存页)并注册为userfaultfd。 - 当某线程访问该内存(或进行数据交换)时会触发缺页异常,从而将控制权交给userfaultfd 的 uffd monitor 线程。
- 利用
uffd monitor线程实现一些恶意操作,例如sleep在那里造成UAF、double fetch将某线程的数据覆写、或对某线程读写的内核对象释放掉后再分配到我们想要的地方。
在较新版本的内核中修改了变量 sysctl_unprivileged_userfaultfd 的值
int sysctl_unprivileged_userfaultfd __read_mostly;
//...
SYSCALL_DEFINE1(userfaultfd, int, flags)
{
struct userfaultfd_ctx *ctx;
int fd;
if (!sysctl_unprivileged_userfaultfd &&
(flags & UFFD_USER_MODE_ONLY) == 0 &&
!capable(CAP_SYS_PTRACE)) {
printk_once(KERN_WARNING "uffd: Set unprivileged_userfaultfd "
"sysctl knob to 1 if kernel faults must be handled "
"without obtaining CAP_SYS_PTRACE capability\n");
return -EPERM;
}
//...
之前的版本当中 sysctl_unprivileged_userfaultfd 这一变量被初始化为 1,而在较新版本的内核当中这一变量并没有被赋予初始值,编译器会将其放在 bss 段,默认值为 0,意味着只 root用户才能使用 userfaultfd